Main > Micro optimizations & emulation
Today I finally had some time to get back to reicast / dreamcast emulation / open source stuff.
I was playing around inolen’s redream project. Performance was bad so I dived into profiling. It turns out redream was miscalculating the fastmem compile flag.
Of course, I couldn’t resist and started doing differential profiling. Looking at redream vs reicast, reicast’s TA processing code took 18% of the main emulation thread while redream’s TA processing took far less.
INLINE
void DYNACALL ta_thd_data32_i(void* data)
{
f64* dst=(f64*)ta_tad.thd_data;
f64* src=(f64*)data;
ta_tad.thd_data+=32;
f64 t = src[0];
dst[0]=t;
dst[1]=src[1];
dst[2]=src[2];
dst[3]=src[3];
PCW pcw=(PCW&)t;
u32 state_in = (ta_cur_state<<8) | (pcw.ParaType<<5) | (pcw.obj_ctrl>>2)%32;
u8 trans = ta_fsm[state_in];
ta_cur_state = (ta_state)trans;
bool must_handle=trans&0xF0;
if (unlikely(must_handle))
ta_handle_cmd(trans);
}The code had a few “warning” signs (the use of F64 and %) but I assumed a “modern, smart compiler” will be able to optimize these. It turns out that the generated assembly is quite bad.
// Compiled with Visual Studio 2013 CE
ta_vtx_data32:
0090EE10 sub esp,8
0090EE13 mov eax,dword ptr [ta_tad (0D8E368h)]
0090EE18 mov edx,eax
0090EE20 add eax,20h
0090EE23 mov dword ptr [ta_tad (0D8E368h)],eax
0090EE28 fld qword ptr [ecx]
0090EE2A fst qword ptr [esp]
0090EE2D mov eax,dword ptr [esp]
0090EE30 fstp qword ptr [edx]
0090EE32 fld qword ptr [ecx+8]
0090EE35 fstp qword ptr [edx+8]
0090EE38 fld qword ptr [ecx+10h]
0090EE3B fstp qword ptr [edx+10h]
0090EE3E fld qword ptr [ecx+18h]
0090EE41 movzx ecx,al
0090EE44 shr ecx,2
0090EE47 fstp qword ptr [edx+18h]
0090EE4A and ecx,8000001Fh
0090EE50 jns ta_vtx_data32+47h (90EE57h)
0090EE52 dec ecx
0090EE53 or ecx,0FFFFFFE0h
0090EE56 inc ecx
0090EE57 shr eax,18h
0090EE5A and eax,0E0h
0090EE5F or ecx,eax
0090EE61 movzx eax,byte ptr ds:[0D7DE70h]
0090EE68 shl eax,8
0090EE6B or ecx,eax
0090EE6D mov al,byte ptr ta_fsm (0D7D670h)[ecx]
0090EE73 mov byte ptr ds:[00D7DE70h],al
0090EE78 test al,0F0h
0090EE7A je ta_vtx_data32+77h (90EE87h)
0090EE7C movzx ecx,al
0090EE7F add esp,8
0090EE82 jmp ta_handle_cmd (90E560h)
0090EE87 add esp,8
0090EE8A retOuch. As there is no guarantee that the dst / src pointers do not overlap the compiler was not able to re-order those operations. There is no guarantee that src[0] does not change when dst[..] is written. The compiler is forced to spill to the stack and read back PCW. The compiler also uses x87 instructions to do all that. A recipe for disaster.
At the same time, pcw.obj_ctrl % 32 compiles to
0090EE41 movzx ecx,al
[….]
0090EE4A and ecx,8000001Fh
0090EE50 jns ta_vtx_data32+47h (90EE57h)
0090EE52 dec ecx
0090EE53 or ecx,0FFFFFFE0h
0090EE56 inc ecx My naive thinking was that “% power-of-two” is the same as “& (power-of-two -1)”. I often use % over & because of the easier to read constants. However, this is only valid for unsigned integers. For signed integers, remainder calculation is slightly more involved. Even though obj_ctrl is declared as u8 and can never be negative, it is promoted to an integer before performing the calculation. And integer is signed. The compiler could keep track of the conversions/range of the intermediate integer and generate simpler code, but it didn’t.
This also can be inferred from the assembly. movzx eax,al guarantees that the top 24-bits are zero. Based on the truth table of the and operator and ecx,8000001Fh will never set bit 31 to a non-zero value. Thus, it can be substituted with and ecx,1Fh. Also, the S flag will never be set, so jns will always be taken.
Changing the code to
INLINE
void DYNACALL ta_thd_data32_i(void* data)
{
f64* dst = ( f64*)ta_tad.thd_data;
f64* src = ( f64*)data;
ta_tad.thd_data+=32;
memcpy(dst, src, 32);
PCW pcw = *(PCW*)src;
u32 state_in = (ta_cur_state<<8) | (pcw.ParaType<<5) | ((pcw.obj_ctrl>>2) & 31);
u8 trans = ta_fsm[state_in];
ta_cur_state = (ta_state)trans;
bool must_handle=trans&0xF0;
if (unlikely(must_handle))
ta_handle_cmd(trans);
}fixes the x87 use, the stack spill and the remainder calculation. This code more than two times faster! It improves overall performance by 12% on the test scene. It can be further improved as memcpy compiles to
00F5EDCD mov ecx,8
[.. esi/edi spill to stack]
00F5EDD4 mov edi,eax
00F5EDD6 mov esi,edx
00F5EDE0 rep movs dword ptr es:[edi],dword ptr [esi]
[.. esi/edi restore from stack]… which is still not optimal.
Switching to AVX-intrinsics yields
INLINE
void DYNACALL ta_thd_data32_i(void* data)
{
__m256i* dst = (__m256i*)ta_tad.thd_data;
__m256i* src = (__m256i*)data;
PCW pcw = *(PCW*)src;
*dst = *src;
ta_tad.thd_data += 32;
u32 state_in = (ta_cur_state << 8) | (pcw.ParaType << 5) | ((pcw.obj_ctrl >> 2) & 31);
u8 trans = ta_fsm[state_in];
ta_cur_state = (ta_state)trans;
bool must_handle = trans & 0xF0;
if (unlikely(must_handle))
ta_handle_cmd(trans);
}00B7ED80 mov eax,dword ptr [ecx]
00B7ED82 vmovdqu ymm0,ymmword ptr [ecx]
00B7ED86 mov ecx,dword ptr [ta_tad (0FFD368h)]
00B7ED8C inc dword ptr [SQW (1900778h)]
00B7ED92 vmovdqu ymmword ptr [ecx],ymm0
00B7ED96 add dword ptr [ta_tad (0FFD368h)],20h
00B7ED9D movzx ecx,al
00B7EDA0 shr eax,18h
00B7EDA3 shr ecx,2
00B7EDA6 and eax,0E0h
00B7EDAB and ecx,1Fh
00B7EDAE or ecx,eax
00B7EDB0 movzx eax,byte ptr ds:[0FECE70h]
00B7EDB7 shl eax,8
00B7EDBA or ecx,eax
00B7EDBC mov al,byte ptr ta_fsm (0FEC670h)[ecx]
00B7EDC2 mov byte ptr ds:[00FECE70h],al
00B7EDC7 test al,0F0h
00B7EDC9 je ta_vtx_data32+53h (0B7EDD3h)
00B7EDCB movzx ecx,al
00B7EDCE jmp ta_handle_cmd (0B7E560h)
00B7EDD3 retNice clean avx memory copy. Also note that ta_tad.thd_data += 32; was moved after the data copy. This saves a register and avoids spilling esi to the stack. This is much faster than the memcpy version, boosting overall perf by another 13%. The epilogue could be better. Also, avx is compact, but 256-bit ops are not portable. They are also slower when mixed with non-avx code.
Helping the compiler a bit more by (a) making state_in u32 so that ta_handle_cmd can be directly tail-jumped, reordering the branch also helps
INLINE
void DYNACALL ta_thd_data32_i(void* data)
{
__m128* dst = (__m128*)ta_tad.thd_data;
__m128* src = (__m128*)data;
PCW pcw = *(PCW*)src;
dst[0] = src[0];
dst[1] = src[1];
ta_tad.thd_data += 32;
u32 state_in = (ta_cur_state << 8) | (pcw.ParaType << 5) | ((pcw.obj_ctrl >> 2) & 31);
u32 trans = ta_fsm[state_in];
ta_cur_state = (ta_state)trans;
bool must_handle = trans & 0xF0;
if ( likely(!must_handle))
{
return;
}
else
{
ta_handle_cmd(trans);
}
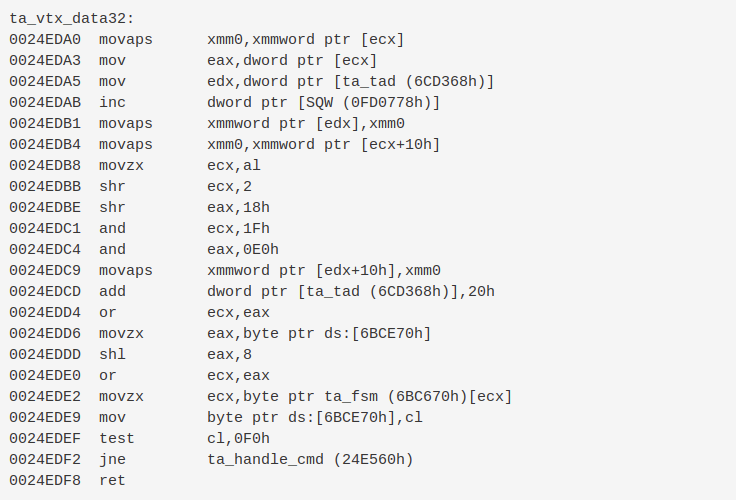
}ta_vtx_data32:
0024EDA0 movaps xmm0,xmmword ptr [ecx]
0024EDA3 mov eax,dword ptr [ecx]
0024EDA5 mov edx,dword ptr [ta_tad (6CD368h)]
0024EDAB inc dword ptr [SQW (0FD0778h)]
0024EDB1 movaps xmmword ptr [edx],xmm0
0024EDB4 movaps xmm0,xmmword ptr [ecx+10h]
0024EDB8 movzx ecx,al
0024EDBB shr ecx,2
0024EDBE shr eax,18h
0024EDC1 and ecx,1Fh
0024EDC4 and eax,0E0h
0024EDC9 movaps xmmword ptr [edx+10h],xmm0
0024EDCD add dword ptr [ta_tad (6CD368h)],20h
0024EDD4 or ecx,eax
0024EDD6 movzx eax,byte ptr ds:[6BCE70h]
0024EDDD shl eax,8
0024EDE0 or ecx,eax
0024EDE2 movzx ecx,byte ptr ta_fsm (6BC670h)[ecx]
0024EDE9 mov byte ptr ds:[6BCE70h],cl
0024EDEF test cl,0F0h
0024EDF2 jne ta_handle_cmd (24E560h)
0024EDF8 retAnother 5% overal perf win. Most of this comes from the SSE vs AVX. ta_vtx_data32 now takes 0.72% at 225 fps vs 18% at 170 fps. This extrapolates to 0.55% at 170fps for the new code.
On the limited test scene, we went from 170-ish fps to 225ish. This is a HUGE 32% performance increase just from editing a few lines. I haven’t looked yet at the generated arm code, but it is plausible this gains 3-4% for the arm side as well (ported to NEON ofc). Funny how improving a function that cost us 18% of the time gave a 32% performance boost. Modern OOO CPUs are /very/ hard to profile.
The original code was micro-optimized for cortex-a8, without considering x86 performance. That micro-optimization also had a fatal mistake, forcing a float -> integer move. I remember writing this code and thinking “mnn this stinks, I’ll take a look at the generated assembly later”. As this code is run 1-10 million times per second even tiny improvements have a big effect on the overall performance.
So, do micro optimizations matter? Based on this example, only if you don’t make things worse while doing them. Looking at the generated assembly and benchmarking on all relevant platforms helps.loc